MiniMax海螺视频团队首次开源:Tokenizer也具备明确的Scaling Law
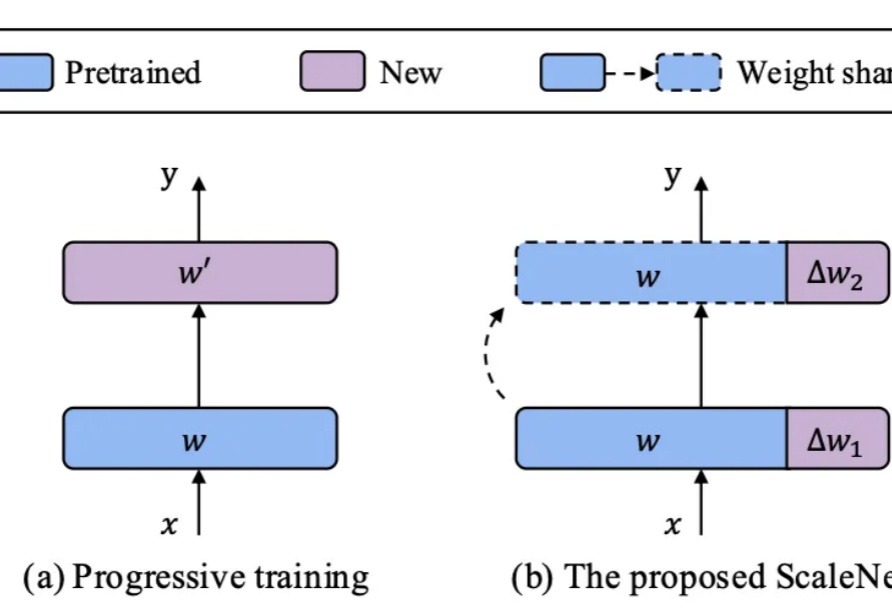
MiniMax海螺视频团队首次开源:Tokenizer也具备明确的Scaling LawMiniMax海螺视频团队不藏了!首次开源就揭晓了一个困扰行业已久的问题的答案——为什么往第一阶段的视觉分词器里砸再多算力,也无法提升第二阶段的生成效果?翻译成大白话就是,虽然图像/视频生成模型的参数越做越大、算力越堆越猛,但用户实际体验下来总有一种微妙的感受——这些庞大的投入与产出似乎不成正比,模型离完全真正可用总是差一段距离。
来自主题: AI技术研报
8576 点击 2025-12-22 17:07